
Sam Altman & Ilya Sutskever: ¿por qué temerle a la IAG? (tomo II)

Este es el segundo tomo de nuestra serie de artículos en los que presentaremos las opiniones de célebres Científicos, CEO's y expertos sobre AI sobre la Inteligencia Artificial General y su impacto en nuestra sociedad.
Recientemente poderosas voces han expresado su opinión y decidimos compartir con nuestra comunidad un compendio sobre los argumentos más importantes en sus discursos, nos concentraremos en los siguientes puntos:
- ¿Es posible la AGI con las técnicas actuales?
- ¿Es necesario regular la investigación e implementación de los modelos de AI?
En esta edición nos vamos a concentrar en la opinión de dos actores esenciales en el desarrollo de ChatGPT, quienes en la última semana han estado en la boca de toda la comunidad de AI y posiblemente también en la de gran parte del público general.

Al final del texto explicaremos un experimento muy interesante que involucra Aprendizaje por Refuerzo y Modelos de Lenguaje que posiblemente haya moldeado la opinión de ambos sobre la regulación de los modelos de AI.
¿Quién es Ilya Sutskever?
Nació en Rusia sin embargo toda su carrera profesional como científico de la computación la desarrolló en Canadá, su asesor de tésis doctoral es ni más ni menos que Geoffrey Hinton de quien hablaremos en otra de estas ediciones.
Fue uno de los miembros en el consejo de OpenAI posiblemente involucrado en la destitución de Sam Altman de la cual hablaremos mas adelante. Hablando sobre sus trabajos científicos pienso que los puntos claves son los siguientes:
- Desarrollo junto a Hinton y Krizhevsky de la arquitectura Alexnet.
- Participación en el desarrollo de TensorFlow.
- Su nombre también aparece en el artículo de AlphaGo.
A partir del lanzamiento de ChatGPT el interés y preocupación de varios sectores crecieron enormemente y él junto a numerosas personalidades firmaron un manifiesto pidiendo que se regulara el desarrollo e investigación de la IA con el fin de minimizar los riesgos existenciales de la humanidad.
¿Quién es Sam Altman?
Aunque comenzó sus estudios en Stanford University sobre Ciencias de la Computación, nunca los terminó y se dedicó a desarrollar algunos otros proyectos como una red social llamada Loopt. Junto a Elon Musk y otras personas fundó OpenAI la cual es una de las compañías más influyentes en la historia de la Inteligencia Artificial.

Aunque su labor siempre ha estado más cercana a la gestión e inversión de proyectos de IA y no precisamente al desarrollo técnico, su voz es muy poderosa en toda la comunidad y el lanzamiento de ChatGPT es posiblemente una decisión suya. Altman también firmó el manifiesto sin embargo se especula que tiene una actitud más optimista sobre la ayuda de la IA para mejorar a la humanidad.
En Noviembre del 2023 y después de más de 4 años como CEO de OpenAI fue destituido de su cargo aunque solo duró unos días pues el 22 de Noviembre volvió a ser nombrado CEO. El día en el que se escribe este artículo algunas publicaciones sugieren que una carta de investigadores dentro de AI señalando un modelo llamado Q* como riesgoso para la humanidad, podría ser la razón por la que se destituyó inicialmente a Altman, ninguna de esta información está confirmada.
Un ejemplo peligroso de un modelo de lenguaje
Debido a la magnitud de compañías como OpenAI o de proyectos como ChatGPT, tanto desde el punto de vista económico, corporativo e inclusive político, es evidente que la información no es demasiado transparente y la mayor parte de lo que sabemos son necesariamente especulaciones.
Aún así me gustaría señalar una de las pocas evidencias de un experimento que se sabe salió muy mal con Grandes Modelos de Lenguaje, el artículo en el que se describe tiene el título Fine-Tuning Language Models from Human Preferences, ya en alguna edición pasada he hablado sobre lo importante que fue este trabajo para el desarrollo de ChatGPT.

La función de ganancia de estos modelos es supervisada manualmente por seres humanos y recibe el nombre de recompensa, digamos que X fuera nuestro propt y Chat nuestro modelo que deseamos entrenar, el objetivo por supuesto es que el modelo maximice la recompensa determinada por los humanos:

Recordemos que todos estos modelos están basados en un modelo auto-supervisado del lenguaje al que en este caso llamaremos GPT, una de las observaciones más interesantes del artículo que les mencionamos es que no es suficiente con maximizar la recompensa sino se debe de regularizar con la distancia de Kullback–Leibler, es decir que debemos maximizar la función:

Esto quiere decir que nos es suficiente con intentar aproximar las preferencias de los seres humanos sino que el modelo Chat no se debe desviar demasiado del modelo base GPT.
Durante el desarrollo de los experimentos, se cuenta que los programadores cometieron un pequeño error cambiándole el signo a la función de recompensa y lamentablemente se quedaron dormidos lo cual no notaron el error hasta que el modelo había terminado el entrenamiento.
Si el cambio de signo hubiera sido únicamente en la función de recompensa original, entonces maximizar la siguiente función hubiera hecho que el modelo final de resultados muy malos, sin embargo el error afectó a la distancia entre Chat y GPT:
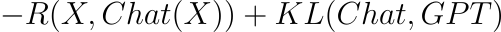
Lo anterior significa que a pesar de elegir respuestas que los humanos no darían al cambiar el signo de la recompensa, el entrenamiento del modelo no permitirá que se aleje demasiado de un modelo GPT el cual conoce bien al lenguaje natural.
Como resultado de lo anterior este Chat arrojó resultados que aunque tenían sentido y eran textos válidos, habían sido descartados por los seres humanos por tener un contenido sexual o grosero.
¿Dónde aprender más sobre Inteligencia Artificial?
- Track de Ciencia de Datos. (49 semanas).
- Machine Learning & AI for the Working Analyst ( 12 semanas).
- Matemáticas para Ciencia de Datos ( 24 semanas).
- Especialización en Deep Learning. (12 semanas).
- Track de Finanzas Cuantitativas (49 semanas)
- Aplicaciones Financieras De Machine Learning E IA ( 12 semanas).
- Las matemáticas de los mercados financieros (24 semanas).
- Deep Learning for Finance (12 semanas).


Premio Nobel de Química: los algoritmos de Baker y Hassabis-Jumper para el diseño de proteínas

Taxonomía de las redes neuronales I: las capas
