
Encajes plurilingües en NLP

El Procesamiento del Lenguaje Natural es uno de los problemas más importantes dentro de Inteligencia Artificial, quizás la principal razón es por sus aplicaciones a un sinfín de problemas en la industria y la academia.
En este artículo hablaremos en particular sobre las aplicaciones a los problemas plurilingües aunque comenzaremos con una breve introducción al NLP en general. Los temas que abordaremos son:
- Procesamiento del Lenguaje Natural
- Deep Learning y los encajes de texto
- Alumni
- ¿Por qué hacer a los encajes plurilingües?
- Meemi: un encaje plurilingüe
- Explicación matemática
- Ejercicios

Para ejemplificar NLP comencemos con un problema sencillo proveniente de la industria y que es relevante para numerosas compañías sin importar su tamaño: la eliminación de textos duplicados. Una de las encarnaciones más obvias de este problema son las descripciones de productos duplicados, ya sean en un contexto de una tienda de retail o las descripciones internas de los productos. Algunas veces el volumen de datos excede el orden de los miles y lo convierte en un problema sumamente laborioso que genera grandes costos de hora-hombre.

Si usted enfrenta un problema similar lo invitamos a contactar a Ezzquad, una compañía asesorada por nosotros quienes son expertos en este tipo de problemas. Su fundador Eligio Andrés Chan España ha tomado numerosos cursos con nosotros.
Dentro del mundo académico también existen numerosos problemas que pueden ser abordados desde el punto de vista de NLP, particularmente dentro de las Ciencias Sociales en donde las fuentes de información comúnmente son textos ya sean archivos históricos, documentos oficiales y más recientemente las interacciones dentro de redes sociales.

Las distintas tareas de NLP como análisis de sentimientos, clusterización, resúmenes, named-entity recognition, etc. han probado ser de gran ayuda para los investigadores en Ciencias Sociales.

Una de nuestras alumnas Daniela González E. estudió con nosotros algunas de estas técnicas para aplicarlas al problema en Chile de la gestión de riesgos por catástrofes. Utilizando los documentos oficiales en distintas administraciones es posible comparar cuantitativamente las distintas maneras de abordar el riesgo, una de las tareas para realizar esto es el análisis de sentimientos.
Deep Learning y los encajes de texto
Las redes neuronales profundas son una familia de modelos que gracias a los Teoremas de aproximación ofrecen solucionar algunos de los problemas más complicados en el análisis de datos. Hasta los años 80’s no era obvio que un conjunto de datos razonable (desde el punto de vista de las aplicaciones industriales y académicas) podrían entrenarse satisfactoriamente. Gracias al trabajo de geniales científicos de la computación como Yann LeCun entre otros, las redes neuronales son el día de hoy el estado del arte para la mayor parte de los problemas de inteligencia artificial.
Una de las aplicaciones más modestas desde un punto de vista de la sofisticación en la arquitectura son los encajes en NLP (aunque existen en otros contextos). Un encaje es una representación vectorial de una familia de palabras.
El encaje más utilizado en procesamiento de lenguaje natural es el conocido como Bolsa de palabras en el que todas las palabras dentro de una familia de textos (conocido como corpus) se ordenan alfabéticamente y se representan por un vector cuya única entrada distinta de cero es igual a uno y esta coincide con su lugar en el orden alfabético que les dimos a las palabras.
Por ejemplo, la primera palabra en el orden alfabético corresponde con este vector:

La penúltima palabra en el orden alfabético corresponde a este vector:

El tamaño de estos vectores es la cantidad de palabras distintas dentro del encaje.
Otros de los encajes que estudiamos en los cursos del Colegio de Matemáticas Bourbaki son por ejemplo Word2vec o GLOVE los cuales son ampliamente utilizados tanto en castellano como en inglés. Los encajes son muy importantes en NLP pues permiten introducir un sesgo semántico sobre el significado de las palabras para que los modelos puedan mejorar su funcionamiento.

Uno de los objetivos principales de los encajes que dependen de redes neuronales es que a diferencia de la Bolsa de palabras, permite representar vectorialmente cercanas a las palabras con significados similares.
Alumni del Colegio de Matemáticas Bourbaki
Además de difundir dentro de la comunidad en Iberoamérica la importancia del Procesamiento del Lenguaje Natural, el objetivo de este artículo es compartir con nuestro alumni contenidos que puedan ser útiles para su preparación como Científicos de Datos.
En lo particular, aquellos estudiantes que hayan cursado los siguientes cursos con nosotros, encontrarán de interés este texto por las siguientes razones:
Machine Learning & AI for the Working Analyst: uno de los primeros ejemplos que resolvimos en el curso fue el análisis de sentimientos, en lo particular platicamos sobre cómo La Policía Nacional en España ha implementado un modelo de clasificación entrenado de manera supervisada para verificar la verosimilitud de una denuncia de robo. Este trabajo fue co-escrito por el Científico de la Computación José Camacho-Callados quien también es co-autor del trabajo principal que presentaremos en este artículo.
Especialización en Deep Learning: durante el primer módulo dedicado a las redes neuronales recurrentes comenzamos con una presentación de los encajes, por ejemplo GLOVE o Word2vec, analizamos cómo estos encajes capturan matemáticamente relaciones semánticas importantes entre las palabras, por ejemplo las analogías. Utilizar estos encajes antes de resolver un problema como por ejemplo los resúmenes de texto -por ejemplo las reseñas de productos de Amazon que utilizamos aquella semana- es fundamental para obtener buenos resultados. En este artículo hablaremos sobre cómo los encajes que estudiamos pueden generalizarse a encajes de dos o más idiomas distintos.
Matemáticas para la Ciencia de Datos: durante el módulo de álgebra nosotros estudiamos las transformaciones lineales, las cuales son fundamentales para comprender técnicas de ciencia de datos como por ejemplo PCA. De igual manera estudiamos las transformaciones ortonormales las cuales son una subfamilia de las transformaciones lineales que permiten preservar las distancias euclidianas. En este artículo hablaremos de cómo utilizar las transformaciones lineales ortonormales para generar encajes plurilingües.
Algunos de los profesores de nuestros cursos son Gerardo Hernández, Ana Isabel Ascencio, Eduardo Ramírez, Francisco Marín, Judith Cerit.
¿Por qué hacer a los encajes plurilingües?
Anteriormente hablamos de cómo los encajes en NLP permiten mejorar el funcionamiento de los algoritmos ya sea los de clasificación, topic modelling o incluso resúmenes de texto, sin embargo los modelos de encajes que han estudiado los alumnos del colegio de matemáticas Bourbaki hasta el momento son todos monolingües.

Si regresamos a las dos aplicaciones de NLP que les propusimos, a saber la eliminación de duplicados y el análisis de sentimientos, un encaje monolingüe podría ser insuficiente. En el caso de los duplicados imaginemos una tienda de retail que cuenta con productos descritos tanto en inglés como en castellano, en el caso del análisis de riesgo en catástrofes pensemos en instituciones internacionales cuyos reportes no precisamente estarán en castellano como aquellos hechos en Chile.
Otro punto importante por el cual podríamos necesitar un encaje plurilingües es algo muy importante para Deep Learning conocido como Transfer learning. La idea principal detrás de esta técnica es que por numerosas razones, los modelos más avanzados de NLP están entrenados en inglés y podrían no aplicar para la creación de modelos que se utilicen en Iberoamérica.
Meemi: un encaje plurilingüe
En el importante artículo Meemi: A Simple Method for Post-processing and Integrating Cross-lingual Word Embeddings, sus autores introducen una técnica para tratar inglés, castellano, alemán, iraní, finés, entre otros dentro de un mismo encaje. Los resultados que se obtuvieron son bastante buenos.

Afortunadamente el código de este modelo ha sido publicado y se puede consultar, en la sección de ejercicios pueden encontrar más información.
Explicación matemática
En esta sección no podremos explicar con detalle el modelo Meemi, aunque es muy importante mencionar que después de haber leído y estudiado este texto no debería de ser un problema muy difícil comprender sus detalles.
La siguiente imagen explica el objetivo de lo que queremos lograr desde un punto de vista vectorial, aunque las palabras “loco” y “chiflado” son distintas, el ángulo entre ellas (su distancia del coseno) no debería de ser muy grande.

Comencemos con un encaje A de un lenguaje y otro encaje B de un lenguaje distinto, nuestro objetivo es generar un encaje C que contenga a los dos encajes anteriores y además satisfaga que las traducciones correspondientes tengan una distancia pequeña.
Los encajes A y B bien entendidos se pueden representar de la siguiente manera:

Es importante notar que estamos suponiendo que tenemos un diccionario con la misma cantidad de palabras en el primero y en el segundo idioma, esto aunque podría parecer un problema en un principio, no representa ninguna complicación. Algo que sí es importante es que ambos encajes deben de estar en la misma dimensión, es decir que se debe cumplir lo siguiente (300 es solo un ejemplo):
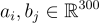
El último de los requisitos es el más importante y es necesario para convertir este problema en uno supervisado: supondremos que tenemos una traducción (una biyección desde un punto de vista matemático) entre las palabras de todos nuestros encajes.
A partir de ahí, el primer enfoque propuesto en el artículo Exploiting similarities among languages for machine translation consiste en resolver el siguiente problema de optimización:

Es decir que estamos buscando una matriz M que sea ortogonal y que defina una transformación lineal de nuestro espacio 300-dimensional en sí mismo, de tal manera que las distancias entre las traducciones sean lo menor posibles. El encaje C consistirá en el encaje B junto a las imágenes del A por la matriz M.
La pregunta que le queda a cualquier científico en este momento es ¿nuestro problema tiene solución?
Problema ortogonal de Procrustes
El problema anterior es equivalente a un importante problema dentro de matemáticas conocido como el problema ortogonal de Procrustes y sus detalles se pueden consultar en el siguiente link. Afortunadamente es posible solucionarlo eficazmente.
Ejercicios
- Desde un punto de vista de las aplicaciones recomendamos ampliamente a los estudiantes visitar el código en el que se implementa Meemi visitando el siguiente enlace. Un ejercicio difícil aunque interesante sería utilizarlo para hacer transfer learning al modelo de resúmenes de texto entrenado en nuestros cursos.
- Desde un punto de vista matemático recomendamos a los estudiantes enviar una explicación en un párrafo explicando la relación entre el problema ortogonal de Procrustes y Análisis de Componentes Principales. Pueden enviar su solución al correo de Alfonso Ruiz y con gusto él la revisará.
Oferta académica
- Track de Ciencia de Datos. (49 semanas).
- Machine Learning & AI for the Working Analyst ( 12 semanas).
- Matemáticas para Ciencia de Datos ( 24 semanas).
- Especialización en Deep Learning. (12 semanas).
- Track de Finanzas Cuantitativas (49 semanas)
- Aplicaciones Financieras De Machine Learning E IA ( 12 semanas).
- Las matemáticas de los mercados financieros (24 semanas).
- Deep Learning for Finance (12 semanas).


Destilación y superalineamiento en Machine Learning (tomo I)

Track de Finanzas Cuantitativas & AI...¿por qué estudiarlo?
