
¿Ley de potencia neuronal is the new statistics?

Una de las preguntas fundamentales de la Ciencia de Datos es ¿cuántos registros son necesarios para entrenar exitosamente un modelo matemático mediante algún algoritmo de Machine Learning? Evidentemente esta es una pregunta terriblemente complicada y general, que podría ni siquiera estar bien formulada sin agregar suficientes hipótesis.
En esta edición de nuestro boletín les hablaremos sobre algunos resultados positivos para el caso particular cuando nuestros modelos son redes neuronales y además incluimos como variable el número de parámetros utilizados.

Estos resultados son absolutamente sorprendentes desde el punto de vista de la teoría clásica de la estadística y sugieren la necesidad de una nueva teoría de los algoritmos de optimización.
El texto está dividido en las siguientes partes:
- Recordatorio sobre modelos lineales y leyes de potencia
- Estadística clásica para Machine Learning
- Leyes de potencia neuronales (o leyes de escala neuronales)
Es importante mencionar que la gran mayoría de los resultados en los que se sugiere que las bases de datos y el error de entrenamiento satisfacen una ley de potencia son empíricos y objeto de una intensa investigación. En este texto hablaremos sobre un caso importante de un Large Language Model llamado Chinchilla, sugerimos al lector revisar algunos de los otros resultados positivos en esta dirección.

Modelos lineales, leyes de potencia y exponenciales
Supongamos que tenemos una variable objetivo que deseamos predecir utilizando únicamente una variable explicativa. Existen muchos modelos matemáticos que podrían ayudarnos a construir una relación funcional entre estas dos variables, sin embargo en este texto nos concentraremos en 3 de ellos:
- Los modelos lineales
- Las leyes de potencia
- Los modelos exponenciales
Para hacer más sencilla la exposición nos concentraremos únicamente en aquellas relaciones decrecientes, es decir que al crecer la variable explicativa, la variable objetivo decrecerá.

Para ser más concretos pensemos en los siguientes ejemplos, recordemos que un modelo matemático podría no acoplarse de manera exacta a un dataset.
- La depreciación de las propiedades (variable objetivo) a medida que pasan los años (variable explicativa).
- La cantidad de ciudades (variable objetivo) con distintos tamaños de población (variable explicativa).
- La cantidad de espuma en una cerveza (variable objetivo) a medida que pasa el tiempo (variable explicativa) después de servirla.
Las ecuaciones de los modelos lineales, ley de potencias y exponenciales son las siguientes, la variable explicativa será la X y la variable objetivo será la Y:
Modelo lineal

Supongamos que tenemos dos coeficientes beta positivos, la siguiente ecuación describe una relación de proporcionalidad constante más una ordenada al origen.
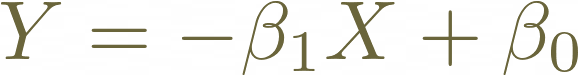
En algunos casos podríamos calcular la depreciación de una propiedad linealmente multiplicando por un factor constante. El coeficiente beta cero es necesario agregarlo porque una propiedad inmediatamente después de ser nueva ya está depreciada.
Ley de potencias
Nuevamente podemos suponer que existen dos coeficientes beta positivos, la siguiente ecuación es lo que normalmente se llama ley de potencias o ley de escalamiento.

No es sorprendente imaginar que a medida que aumentamos la población de una ciudad, la frecuencia con la que encontramos ciudades con esa cantidad de habitantes decrecerá. Existen muchos experimentos en los que se ha comprobado empíricamente que el modelo anterior funciona muy bien para estas variables.
Una gran ventaja de. las leyes de potencias sobre los modelos anteriores es que a pesar de tender a cero, no se anulan a diferencia de los modelos lineales anteriores lo cual es mucho más robusto para el modelado matemático.
Modelo exponencial
Este es uno de los modelos matemáticos más complicados pues reflejan poco control y son muy difíciles de aproximar mediante técnicas clásicas. Hace algunos años una investigación que relaciona la cantidad de espuma en una cerveza con el tiempo recibió el premio Ig Nobel por encontrar una ecuación como la siguiente:

En la ecuación anterior es necesario tener un coeficiente beta uno entre el cero y el uno para que sea verdaderamente decreciente.
Estadística clásica para Machine Learning
En esta sección supongamos que tenemos una variable objetivo Y que es el error en el conjunto de test de un modelo entrenado con Machine Learning, X será el tamaño de nuestro dataset y Z será el número de parámetros en nuestro conjunto de datos.

Tradicionalmente en estadística clásica aplicada a modelos sencillos de machine learning como las regresiones lineales o logísticas, se predice que es necesario que la cantidad de registros X sea más o menos cinco veces el número de variables libres Z de nuestros modelos para tener un error cercano a cero, dicho de otra manera. Dicho de otra manera, el siguiente modelo lineal es una buena aproximación del fenómeno:

Recientemente estadísticos como Emmanuel J. Candès y Pragya Sur demostraron que lo anterior no necesariamente es cierto cuando la cantidad de variables donde vive el dataset es demasiado grande sin embargo sus resultados aún están cerca del régimen lineal.
Notemos que el peor caso posible sería cuando exista una relación exponencial entre el número de registros y el número de variables pues significaría que a medida que nuestros datos tengan más variables, necesitaríamos una cantidad exponencial de registros para entrar modelos que no se equivoquen.
Leyes de potencia neuronales: el caso Chinchilla
A diferencia de los modelos lineales y exponenciales que relacionan el conjunto de nuestros datos con el error y la cantidad de variables, se ha observado un comportamiento parecido al de una ley de potencias en el entrenamiento de las redes neuronales.

En diversas investigaciones recientes se han considerado las siguientes variables asociadas al entrenamiento de una red neuronal:
- El tamaño del error Y
- El tamaño del conjunto de entrenamiento X
- El número de neuronas Z
- El poder de cómputo W
En este artículo solo presentaremos una relación entre las primeras tres variables la cual fue observada y analizada con mucho detalle en el artículo titulado Training Compute-Optimal Large Language Models ( Google DeepMind ).

Los cuatro parámetros de esta ecuación han sido aproximados utilizando el LLM Chinchilla, su dataset de entrenamiento y diversos regímenes computacionales. Notemos la presencial del épsilon positivo que en ese caso señala que el error es más sensible al tamaño del conjunto de nuestros datos que al tamaño de la red neuronal.
Oferta académica
- Track de Ciencia de Datos. (49 semanas).
- Machine Learning & AI for the Working Analyst ( 12 semanas).
- Matemáticas para Ciencia de Datos ( 24 semanas).
- Especialización en Deep Learning. (12 semanas).
- Track de Finanzas Cuantitativas (49 semanas)
- Aplicaciones Financieras De Machine Learning E IA ( 12 semanas).
- Las matemáticas de los mercados financieros (24 semanas).
- Deep Learning for Finance (12 semanas).


Tres aplicaciones de Fourier a problemas financieros
Teoría del caos y redes neuronales
