
Google Translate: un tour de force de Machine Learning

Hace ocho años los sistemas de traducción de Google cambiaron radicalmente, seguramente muchos de los lectores recuerdan las insipinetes traducciones que hacían estos modelos en un inicio. Fue a raíz de dos artículos publicados por Google que la traducción automática con modelos matemáticos evolucionó para siempre, más adelante en el texto les compartiremos los detalles y las referencias de estos trabajos.
Todo comenzó en los laboratorios del Google Brain en donde trabajaron grandes científicos como Andrew Ng, Geoffrey Hinton o Jeff Dean, entre muchos otros. Este laboratorio estaba concentrado especialmente en el desarrollo de modelos neuronales los cuales hasta ese momento funcionaban de maravilla con imágenes pero no necesariamente con textos.

En la actualidad tanto Google Translate como otros traductores realizan traducciones de manera casi impecable y lo pueden hacer en más de 100 idiomas distintos. Las traducciones no son 100% perfectas como no lo son las de los seres humanos inclusive cuando hablan con fluidez un idioma. Es importante mencionar que a partir del 2020 la arquitectura original de Google Translate cambió pues en la actualidad de utilizan los modelos Transformers.
En este pequeño artículo hemos decidido descenbridar uno de los logros más grandes de la inteligencia artificial por medio de siete aspectos en la arquitectura original de Google sin los cuales seguramente no se obtendrían los resultados que sorprendieron al mundo desde septiembre el 2016.
- Redes recurrentes
- Long-Short Term Memory
- Seq2seq
- Atención de Bahadanau
- Bi-direccionalidad
- Profundidad y residuales
- Zero-shot learning
Redes recurrentes
Las primeras redes neuronales que se construyeron son las que hoy se conocen como redes densas las cuáles desafortunadamente no considerar el orden en las características de nuestros imputs.

Ya hemos mencionado que cuando se diseñó la versión moderna de Google Translate ya habían capas convolucionales increíblemente útiles para el procesamiento de imágenes, estas capas sí toman en cuenta la estructura tensorial de las características pues no son invariantes respecto a cualquier permitación que hagamos de nuestras features. Las redes recurrentes recuerdan el orden de nuestras características y esto les permite que las primeras y últimas palabras no tengan la misma importancia en un texto al traducirlo.
Long-Short Term Memory
Una de las grandes desventajas de las redes recurrentes es que realizan una operación similar a la que utilizamos para definir la sucesión de Fibonacci, esto quiere decir que los valores iniciales de Fibonacci tienen una influencia en los valores finales. A pesar de esta influencia, las redes recurrentes no logran construir una memoria de largo plazo, observemos por ejemplo lo que ocurre en la sucesión de Fibonacci, si yo conozco cuál es el número de Fibonacci actual y el número de Fibonacci anterior, yo puedo conocer uno antes del anterior fácilmente.

Si en cambio me encuentro en el Fibonacci un millón, calcular cuál es el Fibonacci cien requiere numerosos cálculos pues no se almacenan los valores. Las arquitecturas LSTM son una ingeniosa solución para este problema pues sí logran contruir dentro de las variables latentes una memoria.
Seq2seq
Los modelos matemáticos necesarios para construir traductores así como los modelos generativos tienen la siguiente complicación: la salida no es únicamente un vector o un número sino una secuencia. Evidentemente el orden de las palabras en nuestra traducción es indispensable. Los modelos Seq2seq son una solución a esta necesidad que utiliza la idea de un encoder-decoder ampliamente requerido en otras áreas de IA.
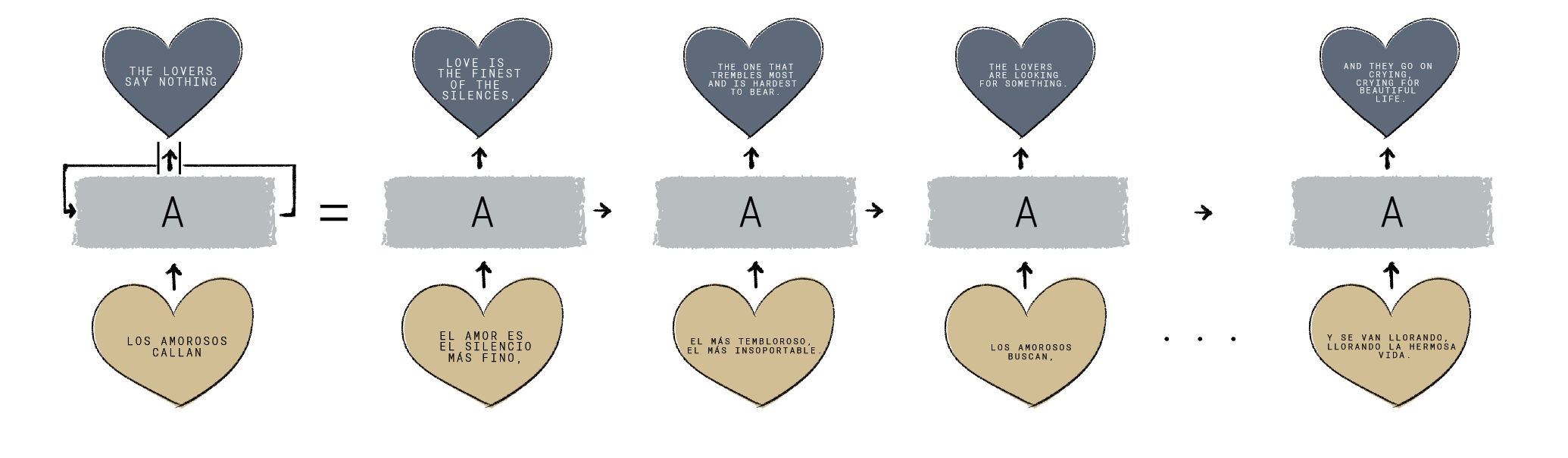
En estos modelos además de utilizar el vector de salida del encoder, se construye una auto-regresión con los tokens anteriores, esto significa que el back-propagation a través del tiempo también debe de utilizarse en el decoder lo cual aumenta considerablemente las complicaciones algorítmicas.
Atención de Bahadanau
La atención de Bahadanau es una adecuación propuesta precisamente para los modelos de traducción de texto dedicada a mejorar la calidad de las variables explicativas tomadas en cuenta en los decoders de los modelos Seq2seq. La principal intención de esta arquitectura es incrementar las correlaciones de manera selectiva entre parabras en nuestra traducción y las del texto que estamos traduciendo. Este mecanismo es la prehistoria de los Transformers modernos que revolucionaron nuevamente a la Inteligencia Artificial.
Bi-direccionalidad
Como lo mencionamos anteriormente las redes recurrentes requieren que elijamos un orden en el que acomodamos a nuestras características, por ejemplo podría ser el mismo que utilizamos para leer en castellano que es de izquierda a derecha. Es muy notable que algunas de las redes recurrentes utilizadas por google no solo leen de izquierda a derecha sino también de derecha a izquierda, esto es completamente inaudito si lo comparamos con nuestra intuición de cómo leemos la información. En defensa de estas arquitecturas bi-direccionales podríamos decir que no es inaudito que cuando estemos leyendo un texto nos regresemos a las palabras inmediatas e inclusive las leamos en desorden.
Profundidad y residuales
Podríamos decir que el arma secreta de las redes neuronales es su capacidad de generalizar y de ser computacionalmente viables inclusive cuando la arquitectura es muy profunda. Los polinomios por ejemplo no tienen esta ventaja respecto al grado que podamos utilizar en la expresión pues rápidamente sobre-ajustan.

Uno de los grandes avances que propuso la arquirectura de Google es modificar ligeramente la composición de capas recurrentes añadiendo un residual con el imput. La intención de esto es que la profundidad no prevenga la aproximación de la función identidad la cual refleja la transferencia de información entre las primeras y las capas más profundas.
Zero-shot learning
Un par de meses después del primer gran salto para la traducción de textos, Google solo podía traducir entre pocos lenguajes e inclusive necesitaba pasar por el inglés para traducir por ejemplo entre el castellano y el francés lo cual evidentemente no era óptimo.

Uno de los grandes avances de Google fue utilizar la transferencia de conocimientos sin la necesidad de cambiar los parámetros de las redes por medio del célebre Zero-shot learning el cual es una herramienta indispensbale en los LLM actuales.
¿Dónde aprender sobre redes neuronales?
En el Colegio de Matemáticas Bourbaki enseñamos con detalle las matemáticas y las bases para que nuestros estudiantes estén listos para aprender los modelos más avanzados de Inteligencia Artificial. Todos los perfiles y necesidades son bienvenidos pues los curso son progresivos. Pueden revisar información en las páginas Track de Finanzas Cuantitativas & AI y Track de Ciencia de Datos.
Compartimos con ustedes algunos de nuestros temarios de cursos por iniciar:
- Track de Ciencia de Datos. (49 semanas).
- Machine Learning & AI for the Working Analyst ( 12 semanas).
- Matemáticas para Ciencia de Datos ( 24 semanas).
- Especialización en Deep Learning. (12 semanas).
- Track de Finanzas Cuantitativas (49 semanas)
- Aplicaciones Financieras De Machine Learning E IA ( 12 semanas).
- Las matemáticas de los mercados financieros (24 semanas).
- Deep Learning for Finance (12 semanas).


Once trivias sobre Matemáticas y Ciencia de Datos

Las matemáticas de los valores faltantes
