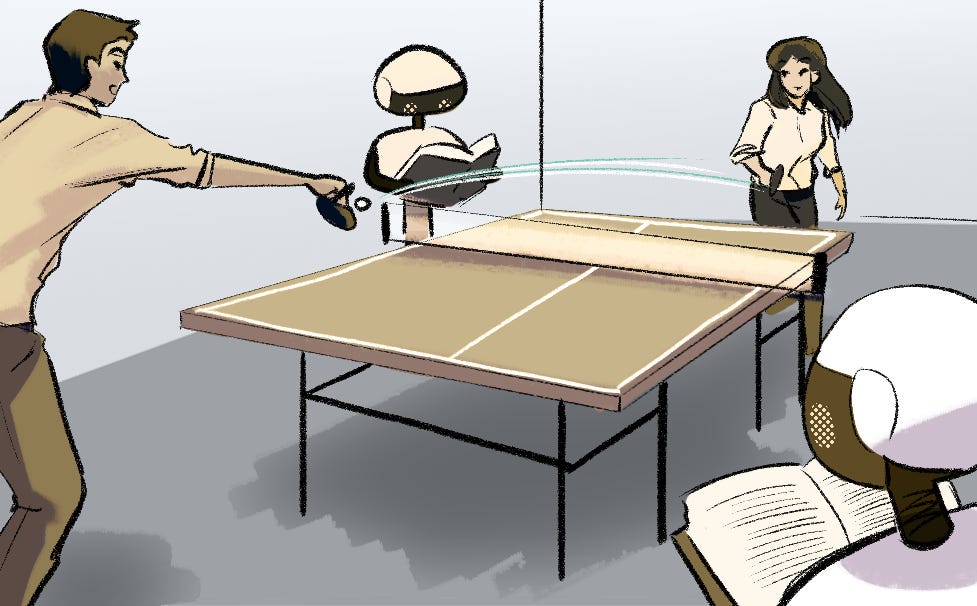
Aprendiendo ping pong ¿supervisado, por imitación o por refuerzo?

Hace algunos días con la fiebre del espíritu olímpico leía un trabajo de investigadores en Google DeepMind en el que lograron entrenar un robot capaz de jugar tenis de mesa de manera competitiva con el nivel de un jugador amateur. El artículo me pareció muy interesante porque propone un acercamiento híbrido entre aprendizaje por refuerzo y aprendizaje por imitación los cuales son dos técnicas en Machine Learning bastante distintas.

En este artículo hablaré sobre tres paradigmas muy importantes que existen en Machine Learning, aunque existen algunos otros estos tres son muy relevantes para la inteligencia artificial en el mismo espíritu que los modelos presentados para el tenis de mesa:
- Aprendizaje supervisado
- Aprendizaje por imitación
- Aprendizaje por refuerzo
Como ya lo mencionamos, en el trabajo de Deep Mind se utiliza tanto aprendizaje por imitación como por refuerzo y el hecho de que el aprendizaje por refuerzo sea una técnica eficaz en machine learning es para mi una gigantesca sorpresa si consideramos los espacios gigantescos en los que se busca optimizar a las funciones.
El tenis de mesa y la inteligencia artificial
Desde que era muy pequeño siempre he sido aficionado al tenis de mesa y me parece un deporte que a pesar de no ser tan exigente físicamente como algunos otros, tiene algunas particularidades que lo hacen extraordinariamente complicado.
Los jugadores de mesa profesionales pronto reconocerán la enorme diferencia que existe entre jugar contra un robot y contra una persona real tomando en cuenta la gran cantidad de variables externas. Los invito a conocer un poco más sobre este deporte en la cuenta de Instagram de mi amigo Miguel Lara quien ha sido seleccionado nacional por México y campeón a nivel nacional.

Cuando pensamos en este deporte desde el punto de vista de la inteligencia artificial es evidente que el aspecto robótico es indispensable y podría ser tan complicado como el modelo matemático que tome las decisiones de cómo jugar. Esto es análogo en la vida real a un jugador muy inteligente y con buena técnica pero como pocas aptitudes físicas, en el tenis de mesa esto es menos evidente que en otros deportes como el básquetbol.
A pesar de esto, inclusive los modelos matemáticos que puedan dirigir las acciones de los robots son muy complicados e inclusive el entrenamiento satisfactorio de ellos sigue siendo un problema pues los modelos matemáticos no tienen tan buen performance como los seres humanos sin importar la capacidad física de los robots. Esto es análogo a problemas como el Ajedrez o el Go en donde a pesar de que las computadoras eran capaces de hacer muchos más cálculos que los seres humanos, aún así no podían jugar mejor que Go hasta el desarrollo en ese caso de las redes neuronales.

Utilizando como ejemplo el tenis de mesa en las siguientes secciones explicaré los conceptos generales de los tres tipos de aprendizaje que mencionamos en la introducción. En cualquiera de los casos se pretende entrenar a un modelo matemático utilizando una base de datos que contenga información sobre el tenis de mesa, la gran diferencia será el tipo de información que se incluye en cada uno de los casos.
Aprendizaje supervisado
Si deseamos entrenar una inteligencia artificial que sea capaz de jugar tenis de mesa por medio del aprendizaje supervisado entonces necesitaríamos tener una familia de observaciones que contengan la siguiente información:
- Variables explicativas, a estas variables se le conocen como X.
- Etiquetas de un experto, a estas variables se le conocen como Y.
En el caso del tenis de mesa podríamos pensar en las variables explicativas como las observaciones de un conjunto de sensores donde el robot recibirá las interacciones con el oponente, pensemos por ejemplo en el sonido que hace la raqueta del oponente al golpear la bola, las pelotas que son golpeadas con mucho spin en tenis de mesa suenan menos que las pelotas que son golpeadas sin spin, otro ejemplo sería la posición en la cual botó la pelota dentro de nuestro lado de la mesa. Incluidas en estas características explicativas podría estar el momento en el partido, el tipo de golpes que se hacen al inicio de un set suelen ser distintos a los que se hacen en puntos decisivos cuando los jugadores desean asegurar el punto.

La variable etiqueta Y en el caso del aprendizaje supervisado sería una combinación de el spin con el que se golpea, la dirección a la que se apunta, la fuerza con la que se golpea, la altura a la que se contacta la pelota y un gigantésco etcétera.
Este tipo de bases de datos son extremadamente difíciles de encontrar pues tendríamos que registrar una cantidad inmensa de estas observaciones para poder aproximar correctamente una curva.
Aprendizaje por imitación: poco supervisado
El aprendizaje por imitación es un poco menos común, consiste en una secuencia de observaciones (X,Y) muy similares a las que teníamos en el caso anterior solo que estas observaciones deben de estar ordenadas una detrás de otra, esto significa que el modelo tomará en cuenta de manera intrínseca el momento del partido en el que se hizo un tiro particular.
La nomenclatura en este caso es un poco distinta:
- A las variables explicativas se les conoce como estados.
- A las variables objetivo se les conoce como acciones.
Un ejemplo muy concreto en el caso del tenis de mesa consistiría en pedirle a un jugador profesional como Miguel Lara que juegue contra algún otro jugador profesional y se registre por medio de sensores en la raqueta pero también en sus cuerpos cómo se golpea la pelota. Con esta información se podría construir una base de datos.
Vale la pena mencionar que este enfoque algunas veces se reduce al aprendizaje supervisado como en los métodos de Behavioural Cloning el cual es un método muy eficiente para resolver estos problemas.
Aprendizaje por refuerzo: muy poco supervisado
El aprendizaje por refuerzo es un caso muy distinto a los anteriores, aunque también está presente el lenguaje de las acciones y de los estados, las bases de datos del aprendizaje por refuerzo no se construye utilizando a un experto como en los casos anteriores sino que se toman decisiones al azar en un proceso que se llama exploración mientras que con una función llamada refuerzo se calcular las recompensas de una acción.

En el caso del tenis de mesa esto es muy distinto pues no estamos indicando cómo se debería de hacer con el registro de los movimientos por ejemplo de Miguel Lara sino que un experto como él estaría juzgando si el tiro al azar que se hizo fue correcto o no lo fue. Es bastante increíble que este método funcione sin embargo así es por ejemplo como se entrenó AlphaGo.
¿Dónde aprender Machine Learning?
En el Colegio de Matemáticas Bourbaki enseñamos con detalle las matemáticas y todos los perfiles y necesidades son bienvenidos, les compartimos las fechas de los cursos que están por iniciar:
- Track de Ciencia de Datos. (49 semanas).
- Machine Learning & AI for the Working Analyst ( 12 semanas).
- Matemáticas para Ciencia de Datos ( 24 semanas).
- Especialización en Deep Learning. (12 semanas).
- Track de Finanzas Cuantitativas (49 semanas)
- Aplicaciones Financieras De Machine Learning E IA ( 12 semanas).
- Las matemáticas de los mercados financieros (24 semanas).
- Deep Learning for Finance (12 semanas).


De Turing a ChatGPT: 10 hitos de la IA

Entscheidungsproblem y el inicio de la computación